# Регулярные выражения
**Вступление**
\
**Регулярные выражения** — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).\
\
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.\
\
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:\
* preg\_match ()
* preg\_match\_all ()
* preg\_replace ()
\
Для работы с ними нужен текст, в котором мы будем искать или заменять подстроки, а также само регулярное выражение, описывающее правило поиска.\
\
Функции на match возвращают число найденных подстрок или false в случае ошибок. Функция на replace возвращает измененную строку/массив или null в случае ошибки. Результат можно привести к bool (false, если не было найдено значений и true, если было) и использовать вместе с if или assertTrue для обработки результата работы.\
\
В JS чаще всего мне приходится использовать:\
* match ()
* test ()
* replace ()
\
Все дальнейшие примеры предлагаю смотреть в . Это удобный и наглядный интерфейс для работы с регулярными выражениями.\
**Пример использования функций**
\
В PHP регулярное выражение — это строка, которая начинается и заканчивается символом-разделителем. Все, что находится между разделителями и есть регулярное выражение.\
\
Часто используемыми разделителями являются косые черты “/”, знаки решетки “#” и тильды “\~”. Ниже представлены примеры шаблонов с корректными разделителями:\
* /foo bar/
* \#^\[^0-9]$#
* %\[a-zA-Z0-9\_-]%
\
Если необходимо использовать разделитель внутри шаблона, его нужно проэкранировать с помощью обратной косой черты. Если разделитель часто используется в шаблоне, в целях удобочитаемости, лучше выбрать другой разделитель для этого шаблона.\
* /http:\\/\\//
* \#http\://#
\
В JavaScript регулярные выражения реализованы отдельным объектом RegExp и интегрированы в методы строк.\
\
Создать регулярное выражение можно так:\
> let regexp = new RegExp("шаблон", "флаги");
\
Или более короткий вариант:\
> let regexp = /шаблон/; *// без флагов*
> let regexp = /шаблон/gmi; *// с флагами gmi (изучим их дальше)*
\
Пример самого простого регулярного выражения для поиска:\
> RegExp: /o/
> Text: hello world
\
В этом примере мы просто ищем все символы “o”.\
\
В PHP разница между preg\_match и preg\_match\_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.\
\
Пример кода на PHP:\
> \ $text = ‘hello world’;
> $regexp = ‘/o/’;
> $result = preg\_match($regexp, $text, $match);
> var\_dump(
> $result,
> $match
> );
> int(1) *// нам вернулось одно вхождение, т.к. после функция заканчивает работу*
> array(1) {
> \[0]=>
> string(1) "o" *// нам вернулось вхождение, аналогичное запросу, так как метасимволов мы пока не использовали*
> }
\
Пробуем то же самое для второй функции:\
> \ $text = ‘hello world’;
> $regexp = ‘/o/’;
> $result = preg\_match\_all($regexp, $text, $match);
> var\_dump(
> $result,
> $match
> );
> int(2)
> array(1) {
> \[0]=>
> array(2) {
> \[0]=>
> string(1) "o"
> \[1]=>
> string(1) "o"
> }
> }
\
В последнем случае функция вернула все вхождения, которые есть в нашем тексте.\
\
Тот же пример на JavaScript:\
> let str = 'Hello world';
> let result = str.match(/o/);
> console.log(result);
> \["o", index: 4, input: "Hello world"]
**Модификаторы шаблонов**
\
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска. Они обозначаются одиночной буквой латинского алфавита и ставятся в конце регулярного выражения, после закрывающего “/”.\
* i — символы в шаблоне соответствуют символам как верхнего, так и нижнего регистра.
* m — по умолчанию текст обрабатывается, как однострочная символьная строка. Метасимвол начала строки '^' соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки '$' соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки.
\
Об остальных модификаторах, используемых в PHP, можно [почитать тут](http://php.net/manual/en/reference.pcre.pattern.modifiers.php).\
\
В JavaScript — [тут](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp).\
\
О том, какие вообще бывают модификаторы, можно [почитать тут](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F#%D0%9C%D0%BE%D0%B4%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%82%D0%BE%D1%80%D1%8B).\
\
Пример предыдущего регулярного выражения с модификатором на JavaScript:\
> let str = "hello world \\
> How is it going?"
> let result = str.match(/o/g);
> console.log(result);
> \["o", "o", "o", "o"]
**Метасимволы в регулярных выражениях**
\
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.\
\
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.\
\
Первый пример, нам надо получить все числа из текста:\
> Текст: “Привет, твой номер 1528. Запомни его.”
\
Чтобы выбрать любое число, надо собрать все числа, указав “\[0123456789]”. Более коротко можно задать вот так: “\[0-9]”. Для всех цифр существует метасимвол “\d”. Он работает идентично.\
\
Но если мы укажем регулярное выражение “/\d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.\
\
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “\*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “{N}”, где N — нужное количество. Или задать “от” и “до”, указав вот так: “{N, M}”.\
\
Сейчас будет пара примеров, чтобы это уложилось в голове:\
> Текст: “Я хочу ходить на работу 2 раза в неделю.”
> Надо получить цифру из тексте.
> RegExp: “/\d/”
> Текст: “Ваш пинкод: 24356” или “У вас нет пинкода.”
> Надо получить пинкод или ничего, если его нет.
> RegExp: “/\d\*/”
> Текст: “Номер телефона 89091534357”
> Надо получить первые 11 символов, или FALSE, если их меньше.
> RegExp: “/\d{11}/”
\
Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:\
* \[a-z]
* \[a-zA-Z]
* \[а-яА-Я]
\
C кириллицей указанный диапазон работает по-разному для разных кодировок. В юникоде, например, в этот диапазон не входит буква “ё”. Подробнее об этом [тут](https://unicode-table.com/en/blocks/cyrillic/).\
\
Пара примеров:\
> Текст: “Вот бежит олень” или “Вот ваш индюк”
> Надо выбрать либо слово “олень”, либо слово “индюк”.
> RegExp: “/\[а-яА-Я]+/”
\
Такое выражение выберет все слова, которые есть в предложении и написаны кириллицей. Нам нужно третье слово.\
\
Помимо букв и цифр у нас могут быть еще важные символы, такие как:\
* \s — пробел
* ^ — начало строки
* $ — конец строки
* \| — “или”
\
Предыдущий пример стал проще:\
> Текст: “Вот бежит олень” или “Вот бежит индюк”
> Надо выбрать либо “олень”, либо “индюк”.
> RegExp: “/\[а-яА-Я]+$/”
\
Если мы точно знаем, что искомое слово последнее, мы ставим “$” и результатом работы будет только тот набор символов, после которого идет конец строки.\
\
То же самое с началом строки:\
> Текст: “Олень вкусный” или “Индюк вкусный”
> Надо выбрать либо “олень”, либо “индюк”.
> RegExp: “/^\[а-яА-Я]+/”
\
Прежде, чем знакомиться с метасимволами дальше, надо отдельно обсудить символ “^”, потому что он у нас ходит на две работы сразу (это чтобы было интереснее). В некоторых случаях он обозначает начало строки, но в некоторых — отрицание.\
\
Это нужно для тех случаев, когда проще указать символы, которые нас не устраивают, чем те, которые устраивают.\
\
Допустим, мы собрали набор символов, которые нам подходят: “\[a-z0-9]” (нас устроит любая маленькая латинская буква или цифра). А теперь предположим, что нас устроит любой символ, кроме этого. Это будет обозначаться вот так: “\[^a-z0-9]”.\
\
Пример:\
> Текст: “Я люблю кушать суп”
> Надо выбрать все слова.
> RegExp: “\[^\s]+”
\
Выбираем все “не пробелы”.\
\
Итак, вот список основных метасимволов:\
* \d — соответствует любой цифре; эквивалент \[0-9]
* \D — соответствует любому не числовому символу; эквивалент \[^0-9]
* \s — соответствует любому символу whitespace; эквивалент \[ \t\n\r\f\v]
* \S — соответствует любому не-whitespace символу; эквивалент \[^ \t\n\r\f\v]
* \w — соответствует любой букве или цифре; эквивалент \[a-zA-Z0-9\_]
* \W — наоборот; эквивалент \[^a-zA-Z0-9\_]
* . — (просто точка) любой символ, кроме перевода “каретки”
**Операторы \[] и ()**
\
По описанному выше можно было догадаться, что \[] используется для группировки нескольких символов вместе. Так мы говорим, что нас устроит любой символ из набора.\
\
Пример:\
> Текст: “Не могу перевести I dont know, помогите!”
> Надо получить весь английский текст.
> RegExp: “/\[A-Za-z\s]{2,}/”
\
Тут мы собрали в группу (между символами \[]) все латинские буквы и пробел. При помощи {} указали, что нас интересуют вхождения, где *минимум* 2 символа, чтобы исключить вхождения из пустых пробелов.\
\
Аналогично мы могли бы получить все русские слова, сделав инверсию: “\[^A-Za-z\s]{2,}”.\
\
В отличие от \[], символы () собирают отмеченные выражения. Их иногда называют “захватом”.\
\
Они нужны для того, чтобы передать выбранный кусок (который, возможно, состоит из нескольких вхождений \[] в результат выдачи).\
\
Пример:\
> Текст: ‘Email you sent was Is it correct?’
> Нам надо выбрать email.
\
Существует много решений. Пример ниже — это *приближенный* вариант, который просто покажет возможности регулярных выражений. На самом деле есть [RFC](https://en.wikipedia.org/wiki/Request_for_Comments), который определяет правильность email. И есть “регулярки” по RFC — [вот примеры](https://fightingforalostcause.net/content/misc/2006/compare-email-regex.php).\
\
Мы выбираем все, что не пробел (потому что первая часть email может содержать любой набор символов), далее должен идти символ @, далее что угодно, кроме точки и пробела, далее точка, далее любой символ латиницы в нижнем регистре…\
\
Итак, поехали:\
* мы выбираем все, что не пробел: “\[^\s]+”
* мы выбираем знак @: “@”
* мы выбираем что угодно, кроме точки и пробела: “\[^\s\\.]+”
* мы выбираем точку: “\\.” (обратный слеш нужен для экранирования метасимвола, так как знак точки описывает любой символ — см. выше)
* мы выбираем любой символ латиницы в нижнем регистре: “\[a-z]+”
\
Оказалось не так сложно. Теперь у нас есть email, собранный по частям. Рассмотрим на примере результата работы preg\_match в PHP:\
> \ $text = ‘Email you sent was . Is it correct?’;
> $regexp = ‘/\[^\s]+@\[^\s\\.]+\\.\[a-z]+/’;
> $result = preg\_match\_all($regexp, $text, $match);
> var\_dump(
> $result,
> $match
> );
> int(1)
> array(1) {
> \[0]=>
> array(1) {
> \[0]=>
> string(13) ""
> }
> }
\
Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:\
\
Было:\
> /\[^\s]+@\[^\s\\.]+\\.\[a-z]+/
\
Стало:\
> /(\[^\s]+)@(\[^\s\\.]+\\.\[a-z]+)/
\
Пробуем:\
> \ $text = ‘Email you sent was . Is it correct?’;
> $regexp = ‘/(\[^\s]+)@(\[^\s\\.]+\\.\[a-z]+)/’;
> $result = preg\_match\_all($regexp, $text, $match);
> var\_dump(
> $result,
> $match
> );
> int(1)
> array(3) {
> \[0]=>
> array(1) {
> \[0]=>
> string(13) ""
> }
> \[1]=>
> array(1) {
> \[0]=>
> string(5) "ololo"
> }
> \[2]=>
> array(1) {
> \[0]=>
> string(7) "example.com"
> }
> }
\
В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.\
\
В PHP можно именовать “захваты”, используя следующий синтаксис:\
> /(?\\[^\s]+)@(?\\[^\s\\.]+\\.\[a-z]+)/
\
Тогда массив матча станет ассоциативным:\
> \ $text = ‘Email you sent was . Is it correct?’;
> $regexp = ‘/(?\\[^\s]+)@(?\\[^\s\\.]+\\.\[a-z]+)/’;
> $result = preg\_match\_all($regexp, $text, $match);
> var\_dump(
> $result,
> $match
> );
> int(1)
> array(5) {
> \[0]=>
> array(1) {
> \[0]=>
> string(13) ""
> }
> \["mail"]=>
> array(1) {
> \[0]=>
> string(5) "ololo"
> }
> \["domain"]=>
> array(1) {
> \[0]=>
> string(7) "example.com"
> }
> }
\
Это сразу +100 к читаемости и кода, и регулярки.\
**Примеры из реальной жизни**
**Парсим письмо в поисках нового пароля:**
\
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. Текст может быть либо на английском, либо на русском:\
> Текст: “пароль: \f23f43tgt4\” или “password: \wh4k38f4\”
> RegExp: “(password|пароль):\s\(\[^<]+)<\\/b>”
\
Сначала мы говорим, что текст перед паролем может быть двух вариантов, использовав “или”.\
Вариантов можно перечислять сколько угодно:\
> (password|пароль)
\
Далее у нас знак двоеточия и один пробел:\
> :\s
\
Далее знак тега b:\
> \
\
А дальше нас интересует все, что не символ “<”, поскольку он будет свидетельствовать о том, что тег b закрывается:\
> (\[^<]+)
\
Мы оборачиваем его в захват, потому что именно он нам и нужен.\
Далее мы пишем закрывающий тег b, проэкранировав символ “/”, так как это спецсимвол:\
> <\\/b>
\
Все довольно просто.\
**Парсим URL:**
\
В PHP есть клевая функция, которая помогает работать с урлом, разбирая его на составные части:\
> \ $URL = "";
> $parsed = parse\_url($URL);
> var\_dump($parsed);
> array(5) {
> \["scheme"]=>
> string(5) "https"
> \["host"]=>
> string(14) "hello.world.ru"
> \["path"]=>
> string(16) "/uri/starts/here"
> \["query"]=>
> string(15) "get\_params=here"
> \["fragment"]=>
> string(6) "anchor"
> }
\
Давай сделаем то же самое, только регуляркой? :)\
\
Любой урл начинается со схемы. Для нас это протокол http/https. Можно было бы сделать логическое “или”:\
> (http|https)
\
Но можно схитрить и сделать вот так:\
> http\[s]?
\
В данном случае символ “?” означает, что “s” может есть, может нет…\
\
Далее у нас идет “://”, но символ “/” нам придется экранировать (см. выше):\
> “:\\/\\/”
\
Далее у нас до знака “/” или до конца строки идет домен. Он может состоять из цифр, букв, знака подчеркивания, тире и точки:\
> \[\w\\.-]+
\
Тут мы собрали в единую группу метасимвол “\w”, точку ”\\.” и тире ”-”.\
\
Далее идет URI. Тут все просто, мы берем все до вопросительного знака или конца строки:\
> \[^?$]+
\
Теперь знак вопроса, который может быть, а может не быть:\
> \[?]?
\
Далее все до конца строки или начала якоря (символ #) — не забываем о том, что этой части тоже может не быть:\
> \[^*#$]+*
\
Далее может быть #, а может не быть:\
> \[*#]?*
\
Дальше все до конца строки, если есть:\
> \[^$]+
\
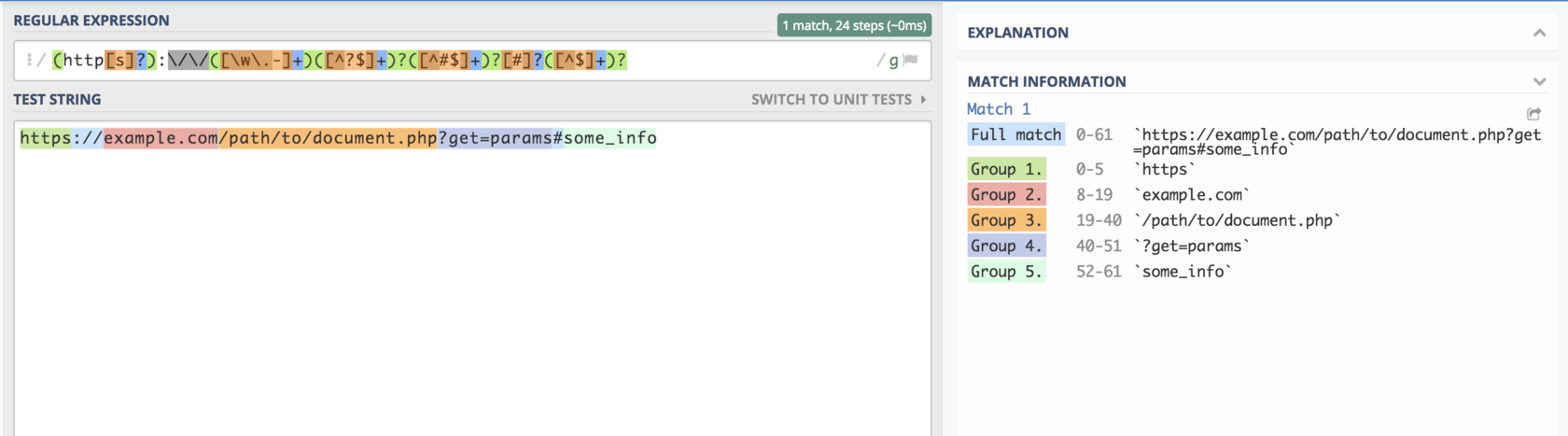
Вся красота в итоге выглядит так (к сожалению, я не придумал, как вставить эту часть так, чтобы Habr не считал часть строки — комментарием):\
> /(?\http\[s]?):\\/\\/(?\\[\w\\.-]+)(?\\[^?$]+)?(?\\[^*#$]+)?\[#]?(?\\[^$]+)?/*
\
Главное не моргать! :)\
> \ $URL = "";
> $regexp = “/(?\http\[s]?):\\/\\/(?\\[\w\\.-]+)(?\\[^?$]+)?(?\\[^*#$]+)?\[#]?(?\\[^$]+)?/”;*
> $result = preg\_match($regexp, $URL, $match);
> var\_dump(
> $result,
> $match
> );
> array(11) {
> \[0]=>
> string(61) ""
> \["scheme"]=>
> string(5) "https"
> \["domain"]=>
> string(14) "hello.world.ru"
> \["URI"]=>
> string(16) "/uri/starts/here"
> \["params"]=>
> string(15) "get\_params=here"
> \["anchor"]=>
> string(6) "anchor"
> }
\
Получилось примерно то же самое, только своими руками.\
\
\
**Какие задачи не решаются регулярными выражениями**
\
На первый взгляд кажется, что регулярными выражениями можно описать и распарсить любой текст. Но, к сожалению, это не так.\
\
Регулярные выражении — это подвид формальных языков, который в иерархии Хомского принадлежат 3-ому типу, самому простому. Об этом [тут](https://ru.wikipedia.org/wiki/%D0%98%D0%B5%D1%80%D0%B0%D1%80%D1%85%D0%B8%D1%8F_%D0%A5%D0%BE%D0%BC%D1%81%D0%BA%D0%BE%D0%B3%D0%BE).\
\
При помощи этого языка мы не можем, например, парсить синтаксис языков программирования с вложенной грамматикой. Или HTML код.\
**Примеры задач:**
\
У нас есть span, внутри которых много других span и мы не знаем сколько. Надо выбрать все, что находится внутри этого span:\
> \
> \ololo1\
> \ololo2\
> \ololo3\
> \ololo4\
> \ololo5\
> <...>
> \
\
Само собой, если мы парсим HTML, где есть не только этот span. :)\
\
Суть в том, что мы не можем начать с какого-то момента “считать” символы span и /span, подразумевая, что открывающих и закрывающих символов должно быть равное количество. И “понять”, что закрывающий символ, для которого ранее не было пары — тот самый закрывающий, который обосабливает блок.\
\
То же самое с кодом и символами {}.\
\
Например:\
> function methodA() {
> function() {<...>}
> if () { if () {<...>} }
> }
\
В такой структуре мы не сможем при помощи только регулярного выражения отличить закрывающую фигурную скобку внутри кода от той, которая завершает начальную функцию (если код состоит не только из этой функции).\
\
Для решение таких задач используются языки более высокого уровня.\
**Заключение**
\
Я постарался довольно подробно рассказать об азах мира регулярных выражений. Конечно невозможно в одну статью уместить все. Дальнейшая работа с ними — вопрос опыта и умения гуглить.